Battle With A Phantom WAL segment

While the Heroku Postgres team were trying to close “the follower hole”, we discovered “phantom WAL1 segments”. This was causing recovering standbys that were trying to replay that segment to crash or enter a retry loop. In this article, I’m going to explain what the follower hole is, what the phantom WAL segment is, and how we tackled it.
The phantom WAL segment is a Postgres bug and it is patched with the Postgres release of 2017-08-10. Any Postgres above 9.2.22, 9.3.18, 9.4.13, 9.5.8, 9.6.4 won’t be affected by this.
The Follower Hole
Introduction
For a long time, the Heroku Postgres team had a problem with something we called “the follower hole”. When you promoted a replica/hot standby database (called a “follower” in Heroku Postgres), or when you created a new PITR2 database (use the Heroku Postgres fork/rollback feature), you had to wait until a new base backup was created on the new leader to create any new replica databases that replicate the new leader . The base backup is a binary copy of the database cluster files. It takes however long the file system itself takes to read (and copy) these files, in our case to S3, to take a new base backup. When competing with large or CPU/IO intensive databases, this base backup capture could take a very long time (multiple hours, or more than a day in some cases we’ve seen).
Heroku Postgres terms:
- Follower: a read-only replica database that follows the leader database. Typically used for horizontal read scaling or reporting (learn more)
- Fork: a new database containing a snapshot of an existing database at the current point in time (learn more)
- Rollback: a new database containing a snapshot of an existing database at a given past time (learn more)
- HA plans (HA setup): a database plan comes with a hidden-follower database. Upon the hardware/software failure of the leader, a failover is automatically triggered by our control plane and this hidden-follower will be promoted to replace the leader to minimize the downtime (learn more)
Example of the follower hole
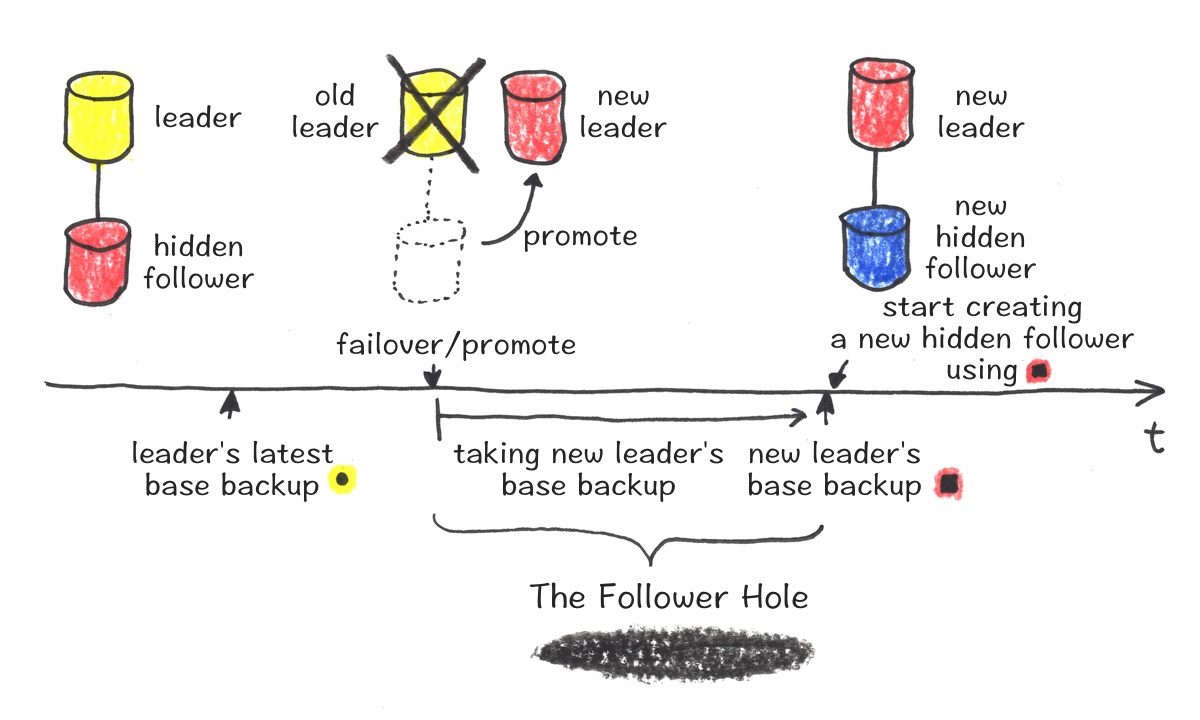
In a diagram above, there is a leader/hidden-follower HA (High Availability) setup with a leader (yellow) and a hidden-follower (red). This diagram shows a failover, where the hidden-follower (red) gets promoted to be the new leader, due to some hardware failure. After the failover, we try to create a new hidden-follower (blue) as soon as possible to maintain the HA setup.
However, our systems were unable to use the base backup from the old leader (yellow), due to how they were segregated in S3. So, a new base backup from the new leader (red square) was required to create a new hidden-follower (blue) with the new leader (red). This means the new hidden-follower (blue) creation can only begin when the base backup (red square) completes.
This was a particularly big issue for customers who wanted to create new followers immediately after promotion. This promotion method is also used with Heroku Postgres plan upgrade, and we were often asked why they weren’t able to create a follower with the new database, or how long it’d take until they’re able to create one.
Let’s say you have a standard-0 plan leader database with a standard-0 follower database. For the plan upgrade, you first create a new standard-2 plan’s follower with the leader, and “promote” the standard-2 plan to make it a leader. Then, you want to have a follower of this standard-2 new leader like you used to have. However, you now have to wait until the base backup of the new standard-2 database is done. The name “follower hole” is exactly coming from here, where you’re missing the follower during this period of time. “Closing the follower hole” means that you can start creating a new standard-2 follower plan right after the promotion.
Follower repointing: we had the same issue with the HA failover that was performed by us. With customers who had (normal) followers with the HA leader, after the failover, we were recreating these followers with a new leader automatically. However, until the base backup is done, customers had to keep using the old, not up-to-date followers (because it is not following the new leader).
This was actually solved by “follower repointing”, which is another huge improvement that we made recently. With follower repointing, we repoint all followers to the new leader after the failover/promotion and continue the replication.
Closing the follower hole
The follower hole was closed by taking advantage of any base backups that are available in all ancestry timelines, from various places in S3. Postgres creates a new timeline whenever an archive recovery (WAL replay) completes so that it can identify the series of WAL records before/after the recovery completion and avoid overwriting WAL files to other timelines. An archive recovery completion here means actions like promoting a hidden-follower or finish the replication (unfollowing). Upon this new timeline creation, a history file is created to record which timeline it branched off from and when.
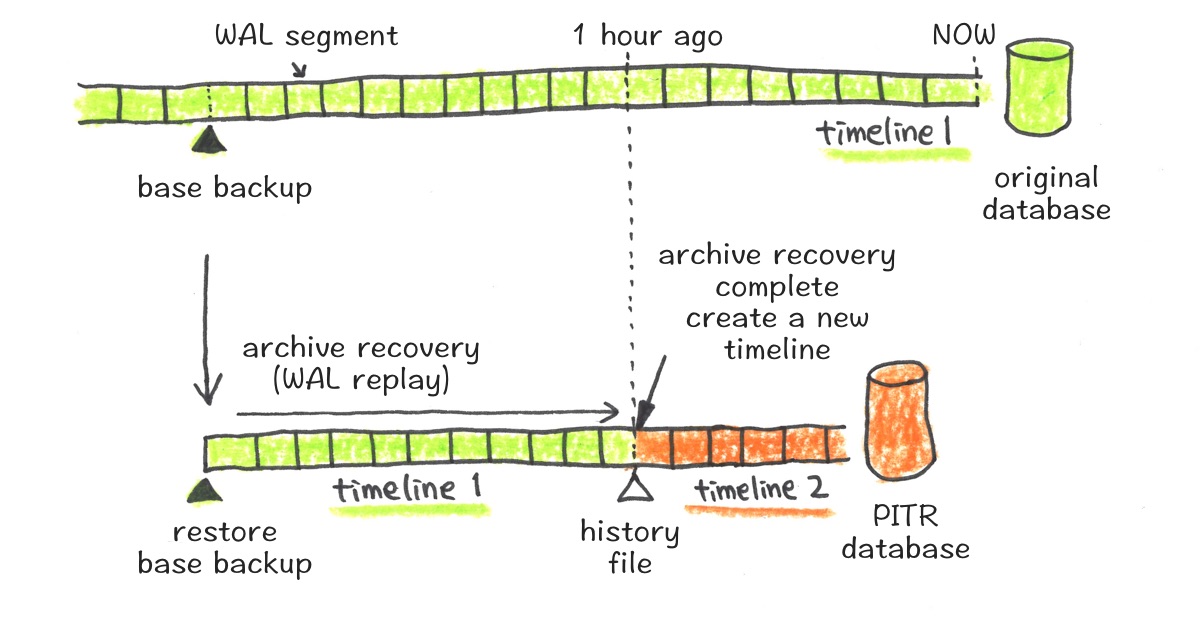
For example, let’s say you have a database with timeline id 1 (light green) and you want to create a PITR database with the target recovery time of 1 hour ago, with this database. First, the PITR database will restore the base backup. Then, it starts an archive recovery (WAL replay) up to the target recovery time (1 hour ago). When it reaches to this time, the archive recovery has completed, so Postgres creates a new timeline with id 2 (previous id + 1, orange). If you write anything to this PITR database, WAL segments will be recorded with the new timeline 2. This PITR database has multiple timelines in its history, 1 (ancestor) and 2 (current).
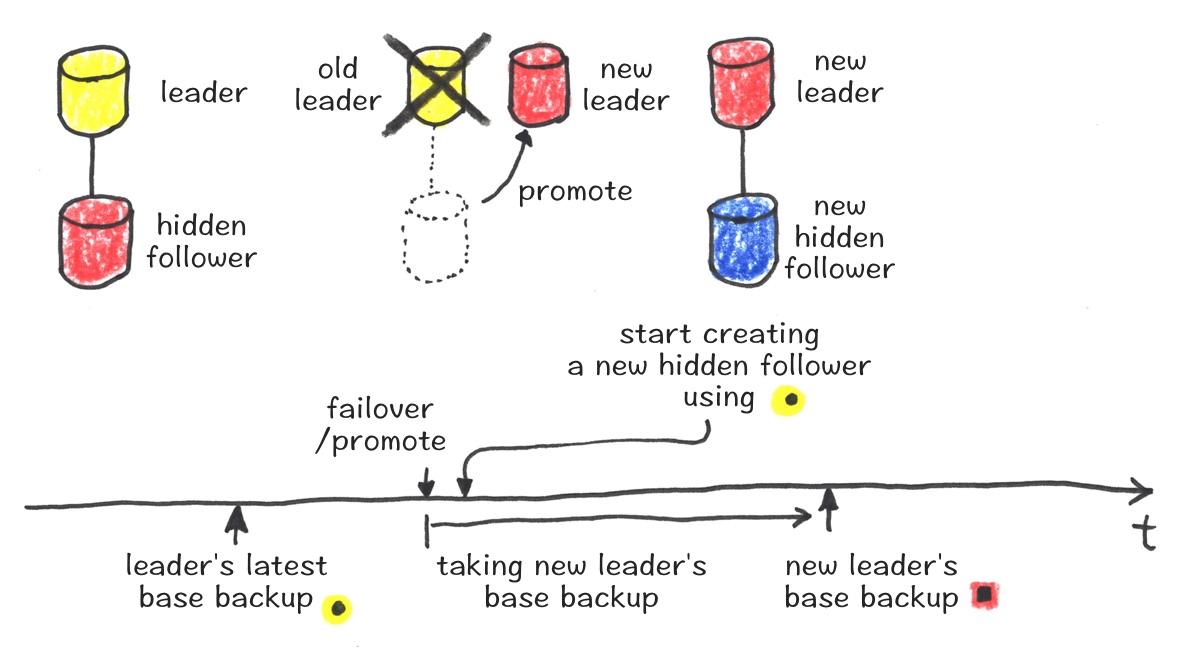
Let’s go back to the same example of the follower hole explanation. To create a new hidden-follower (blue), the new leader’s base backup (red square) was used previously. Now, the old leader’s base backup in the previous timeline (yellow circle) is used and the new hidden-follower recreation happens right away after the promote. Then, the new hidden-follower keeps replaying the WAL of the old leader in the previous timeline first, and at any point when the promote happened and a new timeline was created, it switches the timeline of replication to the current timeline and keeps replaying to be up-to-date of a new leader.
This change introduced the new pattern of replaying the WAL. Prior to this, a new database was not able to be created until the base backup of its leader/parent is available. This means that it was never replaying the WAL from the different timelines, nor it was never replaying the WAL around the timeline switches, it was always replaying the WAL of the current timeline. This was hiding the phantom WAL segment from us for a long time because we never had a chance to read such segment before the follower hole was closed.
The phantom WAL segment
Encounter with a phantom WAL segment
While we were working on closing the follower hole, my colleague Greg Burek found out that there was a certain case that Postgres crashes while replaying WAL. This happened with databases created using the old leader’s base backup, where the base backup was taken during the previous timeline. The error message was something like the following:
Jun 14 02:44:43 [9]: [642-1] LOG: restored log file "000000030000019D00000067" from archive
Jun 14 02:44:43 [9]: [643-1] LOG: unexpected pageaddr 19C/FD000000 in log segment 000000030000019D00000067, offset 0
Jun 14 02:44:43 [9]: [644-1] FATAL: according to history file, WAL location 19D/67000000 belongs to timeline 2, but previous recovered WAL file came from timeline 3
Jun 14 02:44:43 [7]: [4-1] LOG: startup process (PID 9) exited with exit code 1
Jun 14 02:44:43 [7]: [5-1] LOG: terminating any other active server processes
Jun 14 02:44:43 [7]: [6-1] LOG: database system is shut down
As you can see in the error message, it was trying to replay the 000000030000019D00000067 segment. Since that WAL segment should belong to timeline 2 according to a history file, Postgres fails to replay it and crashed. This WAL segment, 000000030000019D00000067, was the source of the trouble. It was a phantom WAL segment!
Here is how creating a follower works in Heroku Postgres.
- Restore the base backup stored in S3
- Replay the WALs stored in S3 (
restore_command) - Once it’s almost caught up to the leader, switch to the streaming replication3 and keep replaying the WALs directly from the leader (
primary_conninfo)
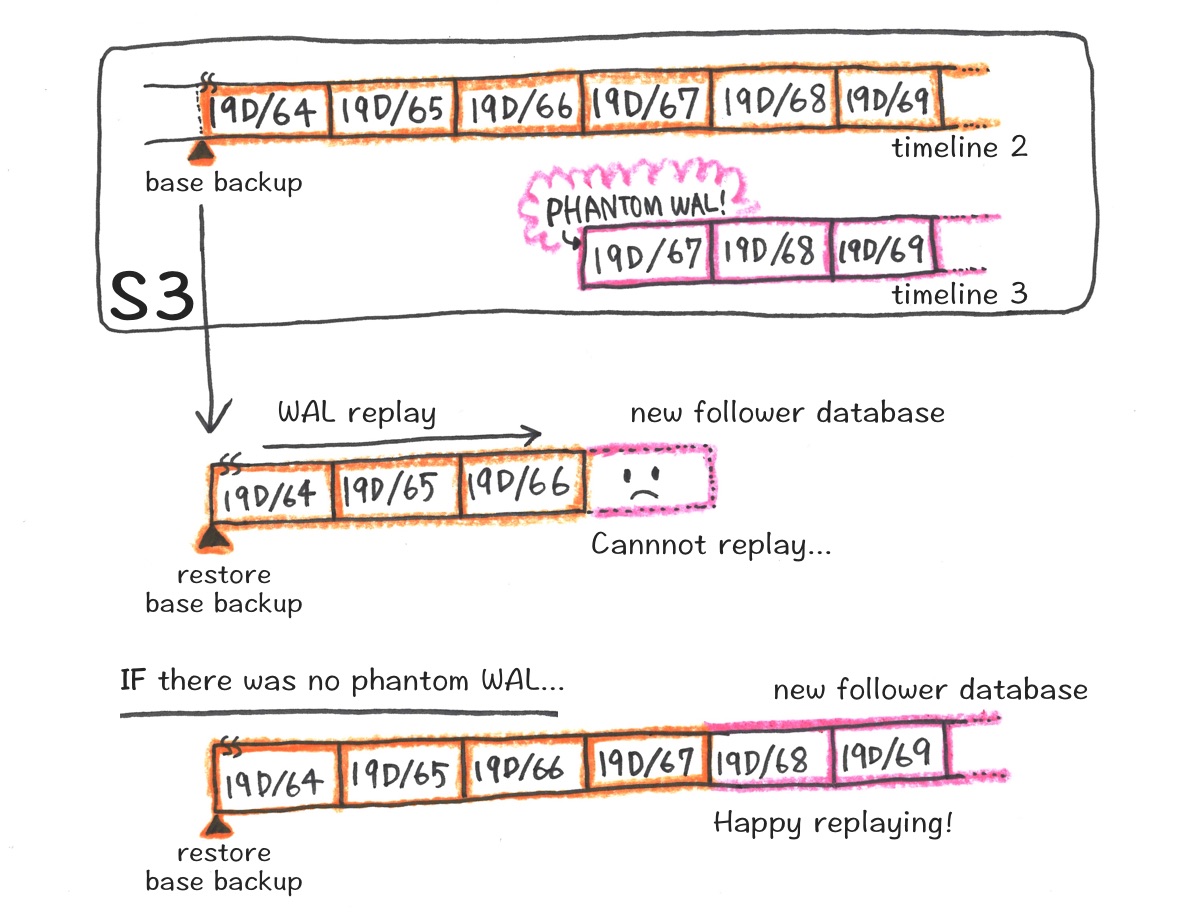
When you create a follower with the base backup with the timeline of its current leader, replaying WAL is simple. You just restore the base backup of the current leader’s timeline and keep replaying whatever WALs in that timeline and switch to the streaming replication.
When the follower is created using the base backup of the leader of its current leader (timeline 2’s base backup), it gets complicated. The base backup restore part is simple, and replaying the WALs of timeline 2 (orange) is also simple. However, when there are two WAL segments with the same log + segment name combination with different timelines (timeline 2’s 19D/67 and timeline 3’s 19D/67), some rules are needed for which WAL to replay and Postgres respects the biggest timeline number’s WAL every time.
While we wanted Postgres to use the timeline 2’s WAL file which should be the “correct one”, it used timeline 3’s WAL file (the phantom WAL file) because it respects the biggest timeline number, and Postgres process exited because it wasn’t able to replay such WAL.
You can find some implementation around here in this Postgres code. Why Postgres is trying to replay the timeline 3’s WAL segment even though 19D/67 doesn’t really belong to timeline 3 according to the history file? That is a good question, which is discussed in the bug report here as well.
WAL file name format: WAL file name is length 24, constructed by 3 parts in hex (each length is 8), timeline id, log, and segment. For the case of
000000030000019D00000067in this article, it’s divided like000000030000019D00000067, which means it’s with timeline id 3, log 19D, and segment 67.
Timeline id would go up with the promote and/or PITR (timeline fork) or reset to 1 with
pg_upgrade. Log part would go up whenever segment reaches to FF, and segment would go up whenever it reached to 16MB (default WAL segment size), whenpg_switch_xlog()or when anarchive_timeoutwas reached and Postgres switched to a new segment file.
Where did it come from?
The phantom WAL segment can be created if the database is promoted at a WAL segment boundary, just after an XLOG_SWITCH record. This means that there is nothing written in a current WAL segment yet, at the time of promotion. This can happen especially when your database is very quiet.
This phantom WAL segment is not an immediate problem, as it’s not a proper WAL segment and it’s not visible to the WAL archiver process. Unless the phantom segment is archived, it won’t be replayed anywhere. However, after a while, in a later checkpoint, Postgres will eventually try to remove this WAL segment file. With Postgres WAL archiving, you can specify the minimum number of past log file segments kept in the pg_xlog directory4 with wal_keep_segments setting. Postgres will try to remove (or “recycle”, by calling rename()) any old files if it’s past wal_keep_segments and can be removed safely (e.g. will not be needed for crash recovery). During this process, Postgres wrongly assumes that the phantom WAL segment is needed to be archived – “Oops, seems like we failed to let it be visible to the archiver process. Let’s archive it!”.
Let me use an actual WAL file name to explain. In the case that I picked up above, 000000030000019D00000067 was the phantom WAL segment file name.
The promotion happened after timeline 2 archived 19D/67 and there was nothing written in 19D/68. Then, the timeline 3 started with 19D/68 but also created a phantom WAL at that time as 19D/67. This 19D/67 (with timeline 3) wasn’t archived immediately.
Heroku Postgres’ wal_keep_segments setting is 61, so somewhere around 61st segments creation after the promotion, Postgres will try to “remove” 000000030000019D00000067. This time, instead of just removing it, Postgres actually marks it as ready to be archived. During our investigation, we observed this phantom WAL creation always happened 60-70 mins or so after promotion. This is interesting but makes sense, because our wal_keep_segments setting is 61, and we also have archive_timeout as 1 min, which means it generates a WAL segment at least once a min for a very quiet database (and we’ve been testing with a quiet database).
The patch in Postgres now does not create a phantom WAL segment, even when the promotion was at a WAL segment boundary.
Solution to the phantom WAL segment
Actually generating a phantom WAL segment should be relatively rare in practice as it requires an idle database with no writes being performed at the timing of a new timeline creation. Attempting to replay such phantom WAL segment is also rare because a newly created follower database needs to use an ancestor’s timeline’s base backup. However, we manage so many databases, we had to do something about it. Our workaround for databases running Postgres versions prior to the patch, is to run a task to look for the phantom WAL segment after the unfollow/promote action, and rename the segment once it’s detected in S3 (we use wal-e for continuous archiving, and we use S3 for the storage). A renamed WAL segment file won’t be considered as a WAL segment, so it won’t be replayed.
In two months, it has saved at least six databases from getting bitten by a phantom WAL segment. This is not a large number compared to how many databases we manage, but it also means there were six fewer pages (otherwise each one would have paged), and six fewer unhappy customers. I’m happy that we have this workaround in place.
Postscript/References
I was actually trying to explain why a phantom WAL was generated more, but it’s getting long so I’m going to skip in this article. If you’re interested in, please read Andres email and commit logs:
- https://www.postgresql.org/message-id/20170619073026.zcwpe6mydsaz5ygd%40alap3.anarazel.de
- https://github.com/postgres/postgres/commit/39e30cbc16cf8d2bd8fb8c5697d02eb220d26ffc
This slide is good to get the idea of Postgres timeline:
Special thanks to reviewers, Peter Geoghegan and Greg Burek. Also thanks for the awesome title calligraphy, Idan Gazit.
-
WAL: Write-Ahead Log ↩︎
-
PITR: Point-in-Time Recovery ↩︎
-
This is technically incorrect, Postgres will switch using streaming replication (
primary_conninfo) and archiving restore (restore_command) whenever it fails, but this explanation is close enough to what is happening. ↩︎ -
pg_xlogdirectory is renamed topg_waldirectory in Postgres 10. ↩︎