Postgres VACUUM and Xmin Horizon
I had a chance to learn about the concept called the “xmin horizon” in Postgres, so I’m leaving a learning memo.
The xmin horizon is also called the oldest xmin, and it tells you “until which point (in terms of transactions) the vacuum process can clean up dead rows”. In other words, VACUUM can’t clean up dead rows after this xmin horizon. When you see a log like “1165 are dead but not yet removable”, it means that there were 1165 dead rows, but VACUUM wasn’t able to clean them up because they are after the xmin horizon.
It is important to make sure that this xmin horizon is not held back, so that VACUUM can do its job!

Dead rows (tuples)
Before talking about the xmin horizon, Let’s do a quick recap of what VACUUM is in Postgres.
As you delete a row, Postgres doesn’t delete that row right away, but instead, it’ll mark such a row as deleted. Once it’s marked as deleted, it becomes a dead row (or tuple1) and will be subject to being removed by VACUUM2. The same thing happens when you update a row, as it is equivalent to “delete and insert” in Postgres. The deleted row (old value row) will become a dead row and will be subject to being removed by VACUUM.
More delete/update happens, more dead rows accumulated. VACUUM is an important process of Postgres to clean up such rows and avoid bloat3.
Let’s think about a simple example. There is a table called colors with two columns, id and color.
- Connection A inserts two rows (blue, red) into the color table
- Connection B updates the red color row to green
- Connection B marks the red color row deleted = dead row
- Connection B inserts a row with the color green
With this, the red color row is now a dead row, subject to being vacuumed, and will be vacuumed once no one is looking at it.
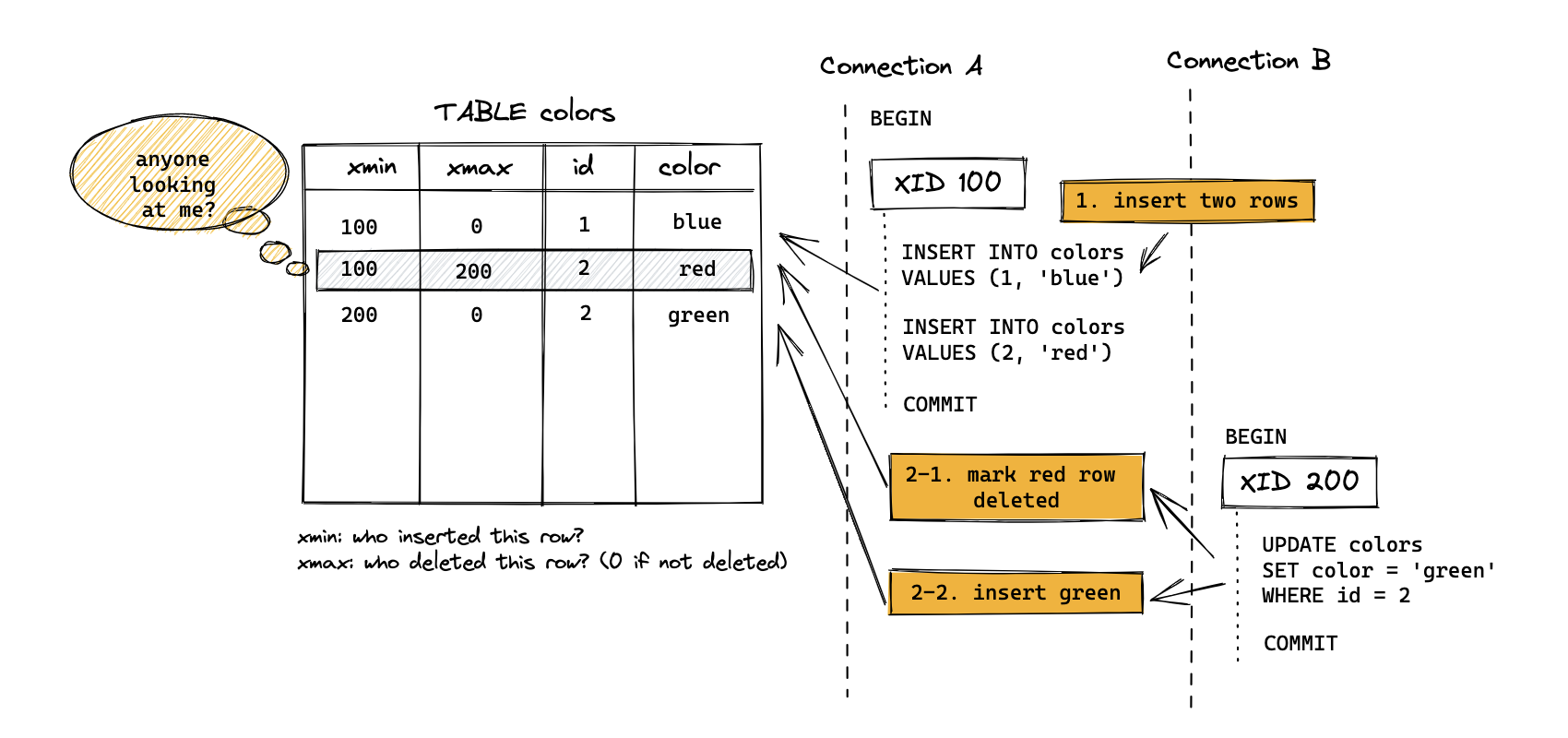
This “once no one is looking at it” is exactly what the xmin horizon tells you. Just because rows are marked as deleted doesn’t mean that Postgres can clean them up, as they might still be visible to someone.
xmin, xmax, and visibility
There are a few terms that I want to clarify, as they really confused me to understand things around here. xmin and xmax are the most confusing ones to me, and used here and there, including the “xmin horizon” and “the oldest xmin”.
For system columns
Every table has several internal columns that are implicitly defined by the system. In each row of the table, there are columns called xmin and xmax:
xmin: The identity (transaction ID) of the inserting transaction for this row version.xmax: The identity (transaction ID) of the deleting transaction, or zero for an undeleted row version.
These values are tied to each row and not directly related to the xmin horizon, so when we talk about the xmin horizon or the oldest xmin, let’s forget about these values (I almost want to call them something like xinserting and xdeleting).
For snapshots
A snapshot is a specific time/version of the database. A snapshot will be generated for each query (with the default READ COMMITTED transaction isolation4) and a query will look at this snapshot to return a result. This allows queries to each have a consistent view of the database, and will never see either uncommitted data during query execution.

In the diagram below, while Q2 is running, even when Q3 updates the value of table1, Q2 won’t see this value because it’s not in the snapshot of Q2.
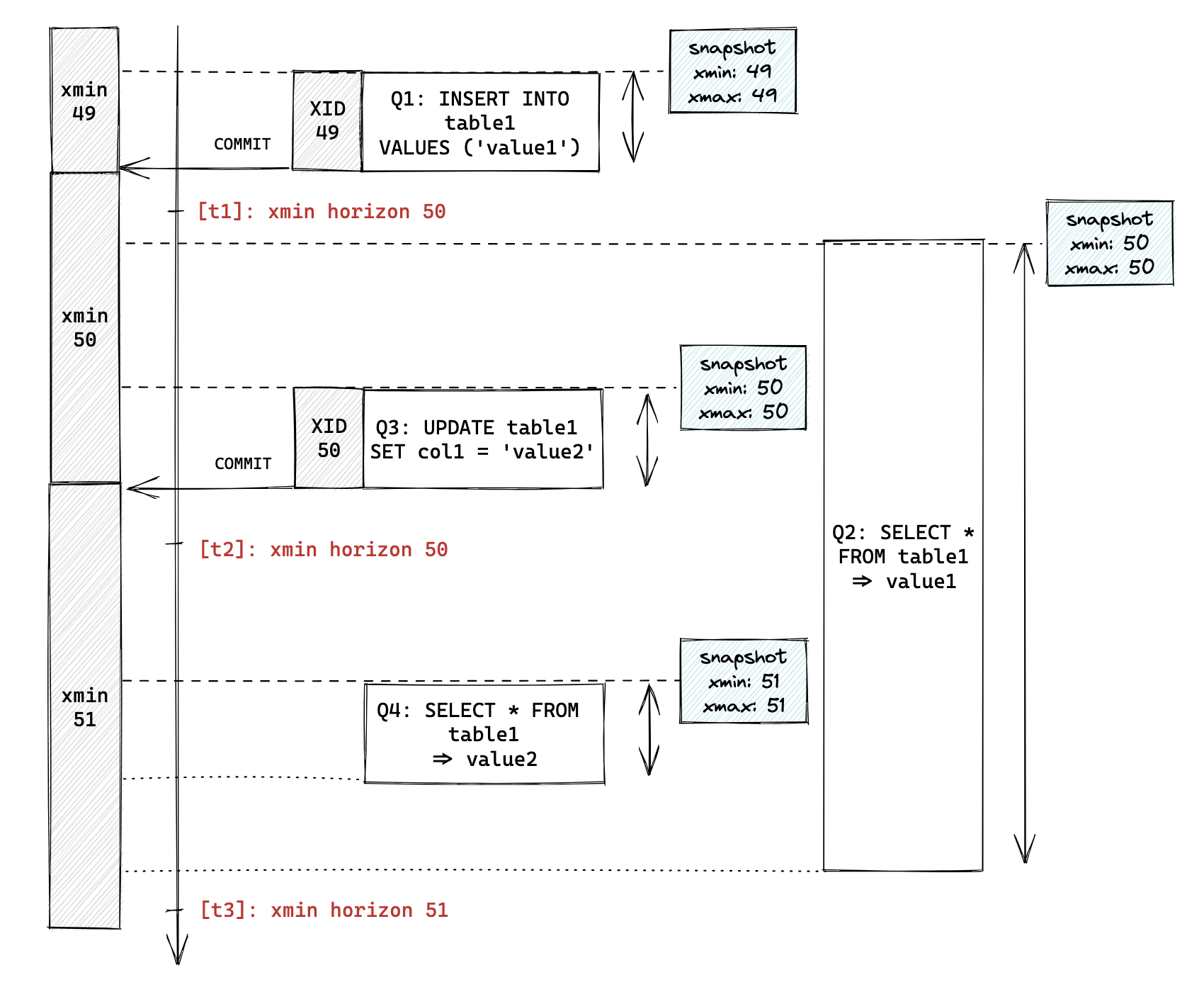
This snapshot also has xmin and xmax. This one is related to the xmin horizon.
xmin: Lowest transaction ID that was still active. All transaction IDs less than xmin are either committed and visible, or rolled back and dead.xmax: One past the highest completed transaction ID. All transaction IDs greater than or equal to xmax had not yet completed as of the time of the snapshot, and thus are invisible.
Applying this to the above diagram:
- t1
- Q1 with XID 49 is committed, the xmin becomes 50
- Q2 starts with the snapshot of the xmin 50 (with value1)
- t2
- Q3 with XID 50 is committed, the xmin becomes 51
- Q4 starts with the snapshot of the xmin 51 (with value2)
With this, we can tell who is looking at what. At the point of t2, the value1 row version is “deleted”, but Q2 is still looking at the value1 row version with xmin 50, so the xmin horizon (or the oldest xmin) of t2 would be 50. At the point of t3, since Q2 is already finished and no one is looking at the xmin 50 row version, the xmin horizon becomes 51.
Holding back the xmin horizon
We talked about how Postgres creates dead rows. We also talked about what the xmin horizon is. Now let’s talk about what can hold back the xmin horizon and potentially prevent VACUUM from running effectively.
There are two aspects that define the xmin horizon:
- Xmin horizon originated from myself (primary)
- Xmin horizon originated from replicas
For the xmin horizon originated from myself (primary server), there are two things that can hold back the xmin horizon:
- Long running transactions
pg_stat_activity.backend_xid: The transaction ID of the backend. When that transaction is still running, you certainly cannot vacuum rows related to that transaction.pg_stat_activity.backend_xmin: The snapshot xmin of the currently running query or transaction. This is explained in the previous section.
- Unfinished prepared transactions
pg_prepared_xacts.transaction: The transaction prepared for a two-phase commit. If this is unfinished and kept around, it can become the oldest xmin. Since prepared transactions are fairly uncommon, you don’t need to worry about this case for the most part.
For the xmin horizon originated from replicas, there are also two things that can hold back the xmin horizon.
- Delayed/bad replication slots5
pg_replication_slots.xmin: The oldest transaction that this slot needs the database to retain. When the replication is delayed or the standby server is down, this value can be “stuck” hence hold back can happen. This value matters only with a physical (streaming) replication withhot_standby_feedback = on.pg_replication_slots.catalog_xmin: The oldest transaction affecting the system catalogs that this slot needs the database to retain. Unlike the abovexmin, this value also matters with a logical replication.
- Long running transactions (standbys with
hot_standby_feedback = on)pg_stat_replication.backend_xmin: The xmin horizon of standby servers. Whenhot_standby_feedbackis on, queries on standbys will act the same as primary regarding the xmin horizon. If queries on standbys are looking at the certain row version, they can’t be removed by VACUUM.
You can check out Laurenz Albe’s blog post for example queries to run to check these values, also what kind of actions to take to resolve the issue.
Running autovacuum too often?
We actually recently had an issue at work that the staging database was running autovacuum way too often. I checked the autovacuum log, and noticed the following log line:
automatic aggressive vacuum of table "template0.pg_catalog.pg_shdepend": index scans: 0
pages: 0 removed, 29 remain, 0 skipped due to pins, 0 skipped frozen
tuples: 0 removed, 3892 remain, 1165 are dead but not yet removable, oldest xmin: 108204095
index scan not needed: 0 pages from table (0.00% of total) had 0 dead item identifiers removed
I/O timings: read: 0.000 ms, write: 0.000 ms avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
buffer usage: 124 hits, 0 misses, 0 dirtied
WAL usage: 0 records, 0 full page images, 0 bytes
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
The important part of this log line is 1165 are dead but not yet removable, oldest xmin: 108204095.
The interesting part is, frequent autovacuum was happening to the pg_catalog related tables. We checked places mentioned above and found out that pg_replication_slots.catalog_xmin was exactly 108204095. This was happening because logical replication was missing a column that was added to the primary and replication had stopped a while ago (“bad replication slot” case).
Once we added the column to the replica manually, replication resumed and catalog_xmin started advancing. The primary was eventually able to run autovacuum with the pg_catalog tables and autovacuum frequency went back to normal. The log lines also became “0 are dead but not yet removable”, meaning VACUUM was able to clean up whatever it wanted to clean up.
Postscript/References
There are several great blog posts around xmin horizon, you can check out them to learn more about it.
- 5mins of Postgres E7: Autovacuum, dead tuples not yet removable, and the Postgres xmin horizon - by Lukas Fittl - This one is good to get the overview of what the xmin horizon is, also touching a real world example. It also has a video, which may be easier to digest.
- VACUUM won’t remove dead rows: 4 reasons why - by Laurenz Albe - Laurenz has many great posts with example queries and logs, it’s easy to understand. This one is definitely one of them.
- MVCC and Garbage Collection in PostgreSQL - by Masahiko Sawada - This one really helped me to understand things around xmin, xmax and visibility. It also helped me to write down this post and many parts overlap. If you didn’t understand some of my posts, maybe it’s good to check out this one to understand the fundamentals of MVCC and GC of Postgres (it’s… in Japanese but maybe a translation tool will do a good job?).
Special thanks to Maciek Sakrejda for reviewing, my sister for putting いらすとや (Irasutoya) illustrations together.
-
I use “rows” in this post, but it is also often mentioned as “tuples”, you can read them interchangeably. ↩︎
-
Technically VACUUM doesn’t “remove” dead rows, but it reclaims storage occupied by dead rows and makes it available for reuse. ↩︎
-
Postgres runs VACUUMs not only to clean up dead rows, but I’ll skip going into the details in this post. ↩︎
-
The snapshot will be generated for a transaction with REPEATABLE READ transaction isolation. ↩︎
-
See caution in the Postgres doc to learn more about what could go wrong with these replication slots. ↩︎